Before the start of the module, I had limited experience using the recently known language models such as ChatGPT or Gemini. However, the process of how these models learn and can perform at such accuracy was a vague subject.
In the first unit of the module, the focus was on introducing machine learning, its past and future and the role it will play in reshaping human life. The lecture cast extinguished the difference between traditional software engineering and machine learning. It was interesting to learn about the automation solutions that the technology offers along with the technical aspects of the learning categories. The first chapter of the introduction to machine learning was a critical part of the reading material for this unit (Miroslav, K. 2021). It has helped me clearly understand the process of feeding learning models training data in form of labelled images and how they are classified based on their attributes.
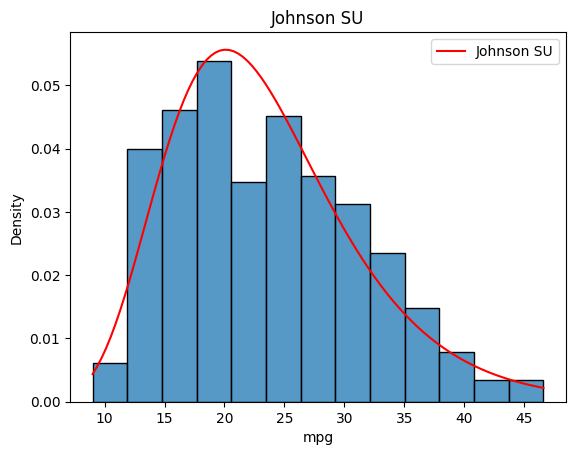
The second unit Introduced the exploratory analysis which is a valuable part of the model-building process (Patil, S., Nagaraja, G. 2020). Although a previous module has covered it briefly, exploring it in detail clarified a few concepts. The fourth section of the first chapter in the introduction to machine learning discussed how it is important to visualise the data and understand the weaknesses within (Miroslav, K. 2021). It was interesting to learn about all the implications and effects they can have on the results of the model. The seminar explored the data analysis tutorial on Google Colab and we had a closer look at the process in a more technical way.
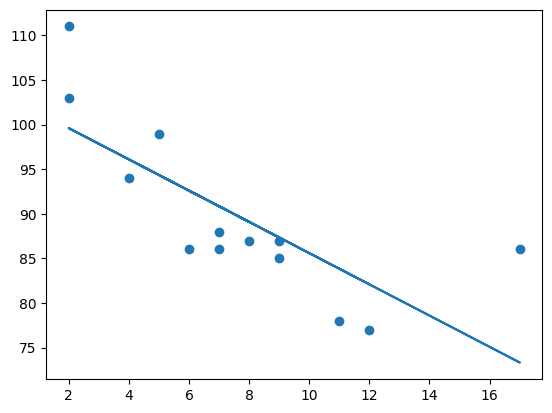
The third unit had insightful details about some of the most common statistical techniques to describe the relationship between the data variables which are correlation and regression. The lecture cast highlighted the mathematical approach to each technique and perfectly explained how to interpret the results in a simpler manner. The machine learning tutorial from CodeBasics showcased the methods and libraries available to use to replicate the process in coding, particularly in Python which has the easiest implementations.
The fourth unit introduced an open-source library called Scikit-learn. Although I was previously unfamiliar with this name, it was very enjoyable to visualise the process of performing linear regression on the given datasets in the activity. The reading material included the user guide of Scikit-learn and how it helps with supervised learning. It is helpful to see how varied the components of the system are.
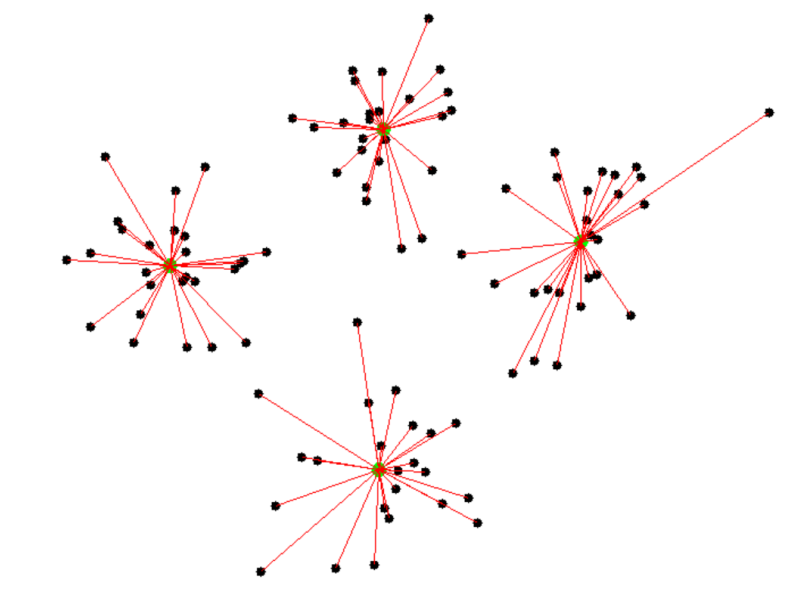
The fifth unit delved into the basics behind clustering and the different techniques employed in evaluating the clusters and interpreting the results. The lecture cast clarified the logic and perfectly explained the evaluation process and the different clustering techniques. Chapter six of the introduction to machine learning briefly talked about the multilayer perceptron and what makes it convenient for the artificial neural network’s architecture (Miroslav, K. 2021).
The sixth unit had more details about the implementation of clustering using python. It was interesting to see how many libraries were available and the role they play in making this accessible as an open source. The group project was due by this unit and the pressure started. Although we had different time zones and personal life schedules, it was not hard to have an effective plan between the group members and the project was delivered on time. The experience was seamless, and I was happy to analyse the data for a business proposal in a group setting as well as my contributions in terms of business question and linear regression analysis.
The seventh unit was a continuation of the learning acquired in the previous reading material. There was an insightful explanation of the basics of human minds and how they work in the lecture cast. Additionally, the analogy with artificial neural networks was delved into among the different functions used such as activation functions. The python activities for this unit helped understand the effect different layers of a neural network model can affect the output accuracy.
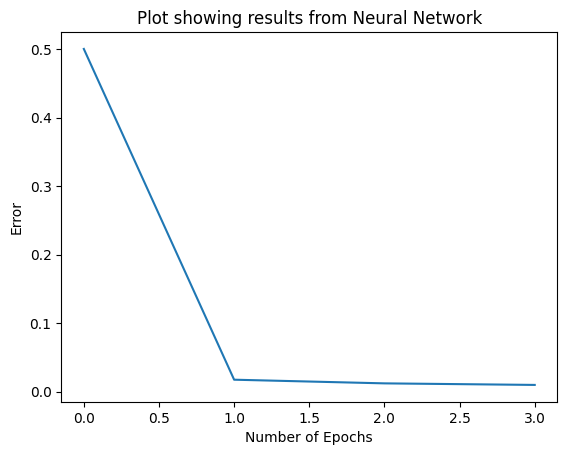
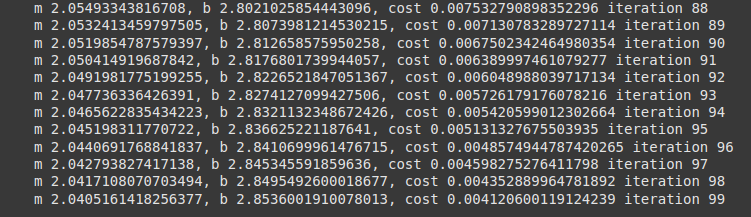
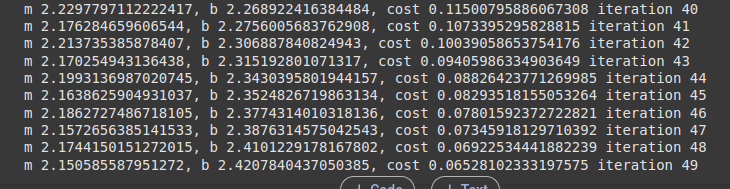
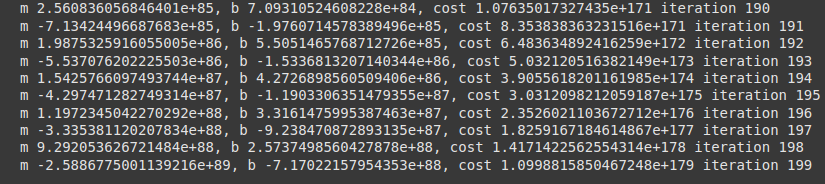
The eight unit was quite enjoyable as it finally made it clear for me how the models are trained using deep learning. The lecture cast explained the backpropagation process and how it helps the model learn from its mistakes by adjusting the neurons’ connection weights after each iteration. The gradient cost function activity cleared some confusion about how to achieve a minimum error loss value while keeping the accuracy high.
The ninth unit was challenging compared to the previous one. The concept of convolutional neural networks was simpler to understand. However, the algorithm behind it was difficult to digest. The lecture cast came in handy in that way, it has simplified each step of the process from object detection to filter learning and filtering to pooling and ending with the output.
The tenth unit was even harder in the aspect of understanding CNN. Visualising learning cycles is always a fun and interactive method to gain in-depth understanding of a particular subject. The seminar content for this week was very helpful in getting ready for next week’s submission and equipped us with all the necessary information.
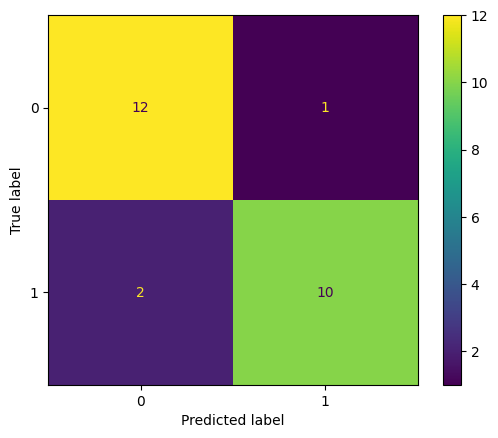
The eleventh unit allowed me to understand the different techniques used to select a specific model and evaluate its performance. The lecture cast was informative in citing popular methods such as cross-validation and the different classification metrics. However, the focus this week was on delivering the summative assessment. Being able to produce an image classification model that is trained and evaluated was a great experience in the end as it made me more comfortable building such systems and ready to work on real-world implementations.
The final unit concluded the module with an insightful visualisation of the future of machine learning and the industry 4.0 revolution. The reading material contained an interesting article about the new trends in machine learning and gave a clear idea about how the future would look like for the industry. The process of building the e-portfolio was simpler in this module after having most of the basis setup on an earlier one.
Throughout the module, I have gained the necessary knowledge into the revolutionary potential of machine learning models and how they will reshape the human future. I feel confident building similar networks that can be implemented in real-world situations by knowing the whole process and having worked on it in both individual and group settings. The knowledge of the weaknesses of the field and the potential threats either economical, physical or ethical will surely play a key role to motivate further research from my side to prevent them.
References
Miroslav, K. (2021) An Introduction to Machine Learning. 3rd Ed. Springer., 3(5), pp.2-4. DOI: https://link-springer-com.uniessexlib.idm.oclc.org/book/10.1007/978-3-030-81935-4
Patil, S., Nagaraja, G. (2020). Exploratory Data Analysis. International Research Journal of Engineering and Technology (IRJET) 7(05). DOI: https://www.academia.edu/download/64615158/IRJET-V7I51256.pdf [Accessed 20 January 2025].
Hutson, M. (2021) Robo-writers: The rise and risks of language-generating AI. Nature, 591(7848), pp.22-25. DOI: https://www.nature.com/articles/d41586-021-00530-0
Tohidul, M. & Nafix, K. (2018). Image Recognition with Deep Learning. IEEE 22(5). DOI: https://ieeexplore.ieee.org/abstract/document/8550021 [Accessed 6 January 2025].
Kaggle (2008). CIFAR-10 Object Recognition in Images. Available via: https://www.kaggle.com/competitions/cifar-10/overview [Accessed 6January 2025].
Keiron, O., Nash, R. (2015). An Introduction to Convolutional Neural Networks. Available via: https://arxiv.org/pdf/1511.08458 [Accessed 23 January 2025].
Mumuni, A., Fuseini, M. (2022). Data augmentation: A comprehensive survey of modern approaches. AI Journal 16(1). DOI: https://www.sciencedirect.com/science/article/pii/S2590005622000911 [Accessed 24 January 2025].
Nazri, M., Atomi, W. (2014). The Effect of Data Pre-processing on Optimised Training of Artificial Neural Networks. Procedia Technology 11(1): 32-39. DOI: https://www.sciencedirect.com/science/article/pii/S2212017313003137 [Accessed 24 January 2025].
Diez, A., Ser, J. (2019). Data fusion and machine learning for industrial prognosis: Trends and perspectives towards Industry 4.0. Information Fusion 10(50): 92-111. DOI: https://www-sciencedirect-com.uniessexlib.idm.oclc.org/science/article/pii/S1566253518304706?via%3Dihub [Accessed 25 January 2025].